In brief
- A hundred lines of code is all you need to create a great virtual assistant with three core components
- Combine a speech recognizer, a core agent and a text-to-speech converter
- You don’t need any coding experience, even non-coders can build it
- This could be your stepping stone to many more projects, the possibilities are endless
More than ever our days are full of things to do (or things we would like to do). So why not use a few simple tools to automate some of the minor tasks or to more easily get the information we need at certain times of the day?
In this short article, we’ll implement a virtual assistant from scratch as well as explaining all the development steps in more detail.
Development environment preparation
Before starting to code the virtual assistant, I suggest setting up a virtual development environment (venv) in order to install all the project dependencies locally, without affecting the system-wide code base.
Here are the command line statements which I prompted to create and activate a venv in my machine (which is running Windows 10):
py -3.11 -m venv va-venv-3.11
.\va-venv-3.11\Scripts\activate
python -m pip install --upgrade pip
If you’re using macOS or Linux distribution as OS, the first command should be replaced by launching the appropriate Python interpreter installed in the system scope:
python3.11 -m venv va-venv-3.11
Any reader who is not familiar with the concept of venv is strongly encouraged to start applying this as good practice when starting a Python project. In addition to separating the dependencies of the latter from the Python modules natively installed by the OS — and consequently, not overwriting them — venv allows users to easily create multiple versions of the project with different versions of the Python interpreter and related modules.
Virtual assistant main components
From a high-level perspective, a virtual assistant can be deconstructed into three main entities:
- A speech recognizer, able to convert the input audio signal into text
- An agent, able to understand the meaning of the incoming text and to compute a related response
- A text-to-speech converter, to convert the mentioned response back to an audio signal
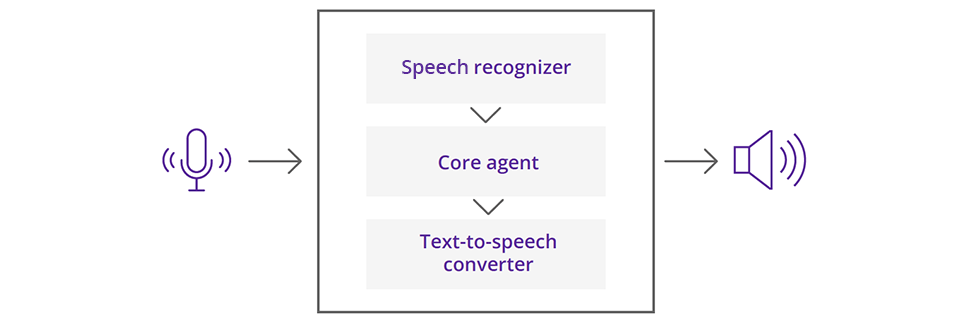
In the next paragraphs, the implementation of these three main components will be treated in more depth.
Speech recognizer implementation
For this particular component of the virtual assistant, the SpeechRecognition library will be used.
In order to install the related modules in the virtual environment, the following statement should be prompted:
pip install SpeechRecognition
Here is a basic usage of the module:
import speech_recognition as sr
# Initialize the speech recognizer...
recognizer = sr.Recognizer()
with sr.Microphone() as audio_source:
recording = recognizer.listen(audio_source)
# The object of the recording is returned after audio signal is detected...
sentence = recognizer.recognize_google(recording)
print(sentence)
The Recognizer class, which is the main entity of the module, is instantiated and connected to the microphone interface in order to listen to incoming signals. As soon as speech is detected, a recording of it is created and is sent to the Google API to convert it to text.
Agent implementation
The core component of the virtual assistant will be a very primitive AI agent, able to compute certain actions depending on the prompt received.
For the project in question, in particular, a very humble Google calendar manager has been implemented.
In order to interface with the Google Calendar API, the following command should be launched to install the related Python module:
pip install gcsa
Here are some lines of code to download the content of the Google Calendar chosen and print it into the console:
import os
from gcsa.google_calendar import GoogleCalendar
# Initialize Google Calendar API...
this_folder = os.path.dirname(__file__)
google_calendar = GoogleCalendar('rodolfo.cangiotti@dxc.com',
credentials_path=os.path.join(this_folder, 'credentials.json'))
for event in google_calendar:
print(event)
For more information about how to configure your Google account and get the file with the related credentials, please refer to this documentation paragraph.
Text-to-speech converter
For the last component of the virtual assistant, the pyttsx3 package will be used even if it has not been actively updated since the summer of 2020.
Here is the pip command to install the related modules:
pip install pyttsx3
For a basic usage of this module, here is a Python script portion:
import pyttsx3
# Initialize text-to-speech engine...
engine = pyttsx3.init()
voices = engine.getProperty('voices')
# Set up the most appropriate voice from the ones supported by the engine...
engine.setProperty('voice', voices[1].id)
# Say something...
engine.say('Hello world!')
engine.runAndWait()
Component aggregation
By combining the code of the above treated components, reorganizing it in a more eloquent way and adding some mechanisms to start or end the conversation with the virtual assistant, the following Python main.py file was produced.
import datetime
import os
import pyttsx3
import speech_recognition as sr
from gcsa.google_calendar import GoogleCalendar
from speech_recognition import UnknownValueError
# Initialize the speech recognizer...
recognizer = sr.Recognizer()
# Initialize text-to-speech engine...
engine = pyttsx3.init()
voices = engine.getProperty('voices')
# Set up the most appropriate voice from the ones supported by the engine...
engine.setProperty('voice', voices[1].id)
# Initialize Google Calendar API...
this_folder = os.path.dirname(__file__)
google_calendar = GoogleCalendar('rodolfo.cangiotti@dxc.com',
credentials_path=os.path.join(this_folder, 'credentials.json'))
# Define some configuration parameters for the script...
AGENT_NAME = 'Penny'
def listen(audio_source):
try:
recording = recognizer.listen(audio_source)
# The object of the recording is returned after audio signal is detected...
sentence = recognizer.recognize_google(recording)
except UnknownValueError:
sentence = None # The engine wasn't able to understand the sentence...
except Exception as e:
print('ERROR>>>', repr(e))
raise e
return sentence
def render(text):
engine.say(text)
engine.runAndWait()
def wait_for_agent_name(audio_source):
while True:
sentence = listen(audio_source)
if not isinstance(sentence, str):
continue
sentence = sentence.strip()
if AGENT_NAME.lower() in sentence.lower():
return
def converse(audio_source):
render('Hello, do you need any help?')
while True:
sentence = listen(audio_source)
if not isinstance(sentence, str):
continue
sentence = sentence.strip()
sentence = sentence.lower()
if 'the appointments' in sentence and \
'today' in sentence:
render(f'Here are the appointments for today, {datetime.date.today()}:')
for idx, event in enumerate(google_calendar, 1):
render(f"Event no. {idx}: {event.summary} "
f"from {event.start.strftime('%H %M')} to {event.end.strftime('%H %M')}")
render("That's all, no other events found!")
elif 'thank you' in sentence or \
'thanks' in sentence:
render("You are welcome, it's a pleasure for me to help you!")
break # Stop conversation...
elif 'never mind' in sentence or \
'no problem' in sentence:
render('Okay, do not hesitate to reach out to me again if you need something else!')
break # Stop conversation...
else:
render("I am afraid I didn't understand what you said. Might you please repeat it?")
def main():
try:
print('Starting agent...')
with sr.Microphone() as audio_source:
while True:
wait_for_agent_name(audio_source)
converse(audio_source)
except KeyboardInterrupt:
print('\nTerminating…')
if __name__ == '__main__':
main()
Conclusions and further developments
The project described in this article is a humble example of the potentials of Python as a programming language. In particular, its simplicity, conciseness and the level of maturity it reached — also considering the variety of external modules available nowadays — demonstrate that with only a few lines of code and even without any in-depth knowledge of the subject, it is possible to create valuable tools.
This project is only aimed at being a starting point, with many possibilities for further improvement. In fact, additional developments might include the usage of a more up-to-date module for text-to-speech conversion, the utilization of more precise speech recognition algorithms and — last but not least — the injection of pre-trained large language models (LLM) in order to allow the conversation with the virtual assistant be wider and more natural with regards to the topics that can be discussed.
References
- Python Launcher for Windows documentation: https://docs.python.org/3/using/windows.html#launcher
- Python venv documentation: https://docs.python.org/3/library/venv.html
- Speech Recognition Python package: https://pypi.org/project/SpeechRecognition/
- gcsa Python package: https://pypi.org/project/gcsa/
- Google Calendar Simple API documentation: https://google-calendar-simple-api.readthedocs.io/en/latest/index.html
- pyttsx3 Python package: https://pypi.org/project/pyttsx3/
- TIOBE Index: https://www.tiobe.com/tiobe-index/
- Build Your Own Alexa With Just 20 Lines of Python: https://plainenglish.io/blog/build-your-own-alexa-with-just-20-lines-of-python-ea8474cbaab7

Rodolfo Cangiotti

Rodolfo is a self-taught software developer, with particular experience in developing web and desktop applications. He holds a bachelor’s degree in electronic music from the Conservatory G. Rossini (Pesaro, ITA), where — even if from a musician’s perspective — he learned the foundations of programming and thinking algorithmically. He is deeply fascinated by the intersection between digital information technologies — in particular, emerging ones like machine learning, AI, IoT — and the arts. He firmly believes in writing clear and eloquent code, in the open-source philosophy, and in sharing knowledge.

